Sequential Contrastive Audio-Visual Learning
Apr 6, 2025·
,
,
,
·
0 min read
Ioannis Tsiamas
Santiago Pascual
Chunghsin Yeh
Joan Serrà
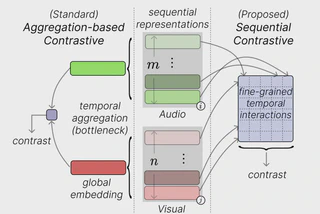 Aggregation- vs. sequence-based contrastive learning
Aggregation- vs. sequence-based contrastive learning
Abstract
Contrastive learning has emerged as a powerful technique in audio-visual representation learning, leveraging the natural co-occurrence of audio and visual modalities in webscale video datasets. However, conventional contrastive audio-visual learning (CAV) methodologies often rely on aggregated representations derived through temporal aggregation, neglecting the intrinsic sequential nature of the data. This oversight raises concerns regarding the ability of standard approaches to capture and utilize fine-grained information within sequences. In response to this limitation, we propose sequential contrastive audiovisual learning (SCAV), which contrasts examples based on their non-aggregated representation space using multidimensional sequential distances. Audio-visual retrieval experiments with the VGGSound and Music datasets demonstrate the effectiveness of SCAV, with up to 3.5× relative improvements in recall against traditional aggregation-based contrastive learning and other previously proposed methods, which utilize more parameters and data. We also show that models trained with SCAV exhibit a significant degree of flexibility regarding the metric employed for retrieval, allowing us to use a hybrid retrieval approach that is both effective and efficient.
Type
Publication
In ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)