Omnilingual MT: Machine Translation for 1,600 Languages
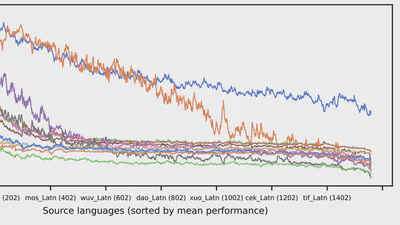
We present OMT, the first MT system supporting more than 1,600 languages, where 1B–8B parameter specialized models match or exceed a 70B LLM baseline, with strong generalization to …
I’m Ioannis Tsiamas,† a Research Scientist and with a PhD in AI at UPC Barcelona, working on multilingual and multimodal representation learning, self-supervised pre-training, and large-scale distributed training. My research has been published at ACL, EMNLP, ECCV, ICASSP, and Interspeech.
I spent 15 months at Meta FAIR, where I led the language expansion of Omnilingual SONAR and contributed to Omnilingual MT, the most massively multilingual systems ever built, spanning thousands languages. I have also conducted research at Apple AI/ML, Dolby, and Zeta Alpha.
My goal is to make AI truly multilingual and accessible across the world’s languages, including the thousands that current systems still cannot reach.
†Note: I publish under ‘Ioannis Tsiamas’, but use Yiannis as prefered name, which is the casual version Ioannis.
Internship at the Omnilingual team of Meta FAIR.
(Aug 2024 - Nov 2025)
Internship at the Machine Translation team of Apple AI/ML.
(Apr 2024 - Jul 2024)
Internship on Audio-Visual Representations at Dolby AI.
(Nov 2023 - Feb 2024)
PhD in Artificial Intelligence at UPC Barcelona.
(Mar 2021 - Jun 2026)
MSc in Artificial Intelligence at the University of Amsterdam.
(Graduated Aug 2020)
MSc in Quantitative Finance at VU University Amsterdam.
(Graduated Oct 2018)
We present OMT, the first MT system supporting more than 1,600 languages, where 1B–8B parameter specialized models match or exceed a 70B LLM baseline, with strong generalization to …
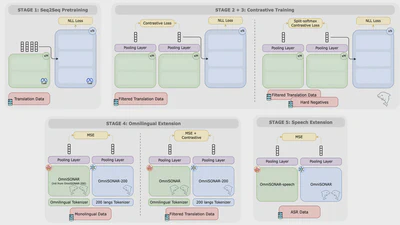
We introduce OmniSONAR, a family of omnilingual cross-lingual and cross-modal sentence embedding models spanning 4,000+ language varieties and natively supporting text, speech, …
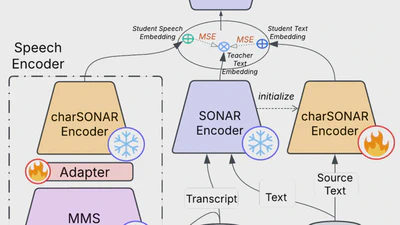
We propose a character-based translation model to improve adaptability to new languages and modalities, particularly for low-resource scenarios. Our method achieves …
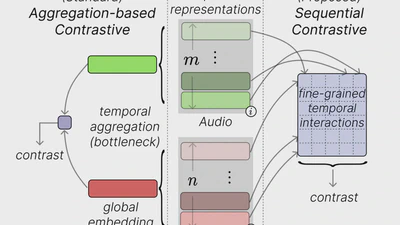
We introduce Sequential Contrastive Audio-Visual Learning (SCAV), a novel method that contrasts non-aggregated sequential representations to learn fine-grained audio-visual …