Masked Generative Video-to-Audio Transformers with Enhanced Synchronicity
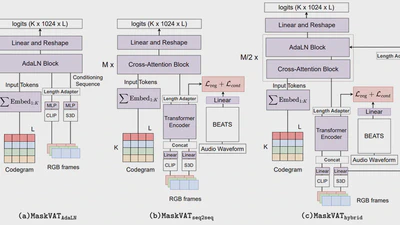
We propose MaskVAT, a generative Video-to-Audio (V2A) model combining a high-quality audio codec with a masked generative model to simultaneously achieve high audio quality, …
We propose MaskVAT, a generative Video-to-Audio (V2A) model combining a high-quality audio codec with a masked generative model to simultaneously achieve high audio quality, …

We present a new method to explain how Transformer models use context for language generation, demonstrating superior alignment with linguistic phenomena and shedding light on the …