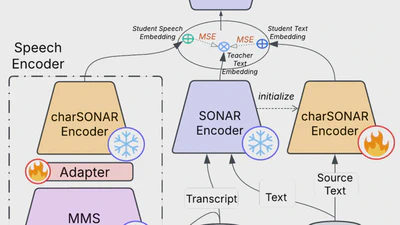
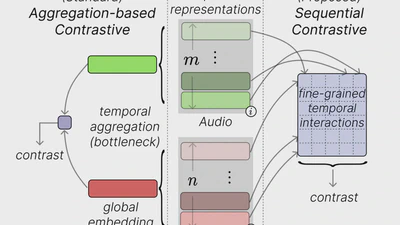
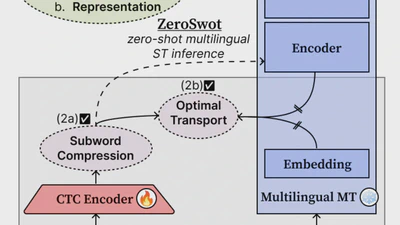
I’m Yiannis Tsiamas, an AI Research Scientist and Ph.D. candidate at UPC Barcelona, working on multilinguality, multimodality, text/speech translation, and representation learning. I have authored papers at top-tier conferences like ACL, EMNLP, and ICASSP, and I’ve had the privilege of contributing to cutting-edge research during internships at Meta, Apple, and Dolby.
I am passionate about languages and my goal is to make AI systems trully multilingual, and accessible to everyone.
†Note: I publish under ‘Ioannis Tsiamas’, but use Yiannis as prefered name, which is the casual version Ioannis.