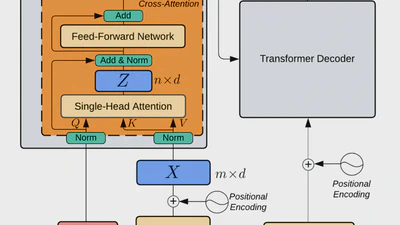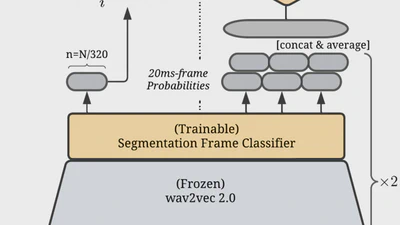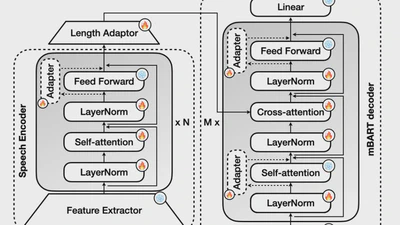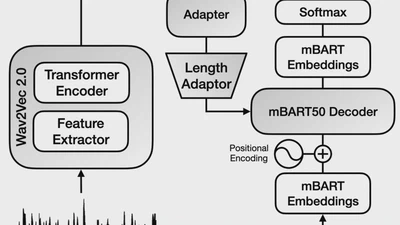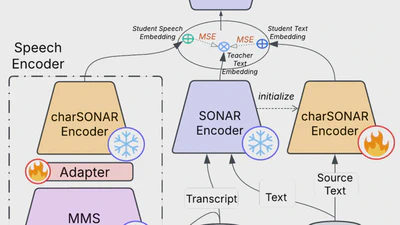
Improving Language and Modality Transfer in Translation by Character-level Modeling
We propose a character-based translation model to improve adaptability to new languages and modalities, particularly for low-resource scenarios. Our method achieves …