Omnilingual SONAR: Cross-Lingual and Cross-Modal Sentence Embeddings Bridging Massively Multilingual Text and Speech
Mar 17, 2026·
,
,
,
,
,
,
,
,
,
,
,
,
,
,
·
0 min read
The Omnilingual SONAR Team
João Maria Janeiro
Core contributor
,
Pere Lluís Huguet Cabot
Core contributor
,
Ioannis Tsiamas
Core contributor
,
Yen Meng
Core contributor
,
Vivek Iyer
Guillem Ramírez
Loic Barrault
Belen Alastruey
Yu-an Chung
Marta R. Costa-Jussà
David Dale
Kevin Heffernan
Jaehyeong Jo
Artyom Kozhevnikov
Alexandre Mourachko
Christophe Ropers
Holger Schwenk
Paul-Ambroise Duquenne
Abstract
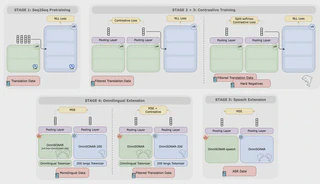
Cross-lingual sentence encoders have traditionally been limited to a few hundred languages, and have sacrificed downstream performance to achieve better alignment across languages, limiting their adoption. In this work, we introduce OmniSONAR, a novel family of omnilingual, cross-lingual and cross-modal sentence embedding models that breaks this barrier. We establish a unified semantic space, natively encompassing text, speech, code and mathematical expressions, while achieving state-of-the-art downstream performance for an unprecedented scale of thousands of languages, from high-resource languages to extremely low-resource varieties. To achieve this scale without representation collapse and while maintaining top-tier performance in the high-resource languages, we employ a progressive training strategy. We first build a state-of-the-art foundational embedding space for 200 languages using an LLM-initialized Encoder-Decoder, combining token-level decoding with a novel split-softmax contrastive loss and synthetic hard negatives. Leveraging this strong foundational space, we expand to several thousands of language varieties via a specialized two-stage teacher-student encoder distillation framework. Further modeling extensions derived from OmniSONAR address long context inputs and token-centric representations. Finally, we demonstrate the cross-modal extensibility of this space by seamlessly mapping 177 spoken languages into it. OmniSONAR redefines the state of the art for multilingual representation learning, halving the cross-lingual similarity search error rate of the previous best models on the 200 languages of FLORES, while also achieving a 15-fold error rate reduction across 1,560 languages on the BIBLE benchmark.
Type
Publication
arXiv