Omnilingual MT: Machine Translation for 1,600 Languages
Mar 17, 2026·
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
·
0 min read
The Omnilingual MT Team
Belen Alastruey
Core contributor
,
Niyati Bafna
Core contributor
,
Andrea Caciolai
Core contributor
,
Kevin Heffernan
Core contributor
,
Artyom Kozhevnikov
Core contributor
,
Christophe Ropers
Core contributor
,
Eduardo Sánchez
Core contributor
,
Charles-Eric Saint-James
Core contributor
,
Ioannis Tsiamas
Core contributor
,
Chierh Cheng
Joe Chuang
Paul-Ambroise Duquenne
Mark Duppenthaler
Nate Ekberg
Cynthia Gao
Pere Lluís Huguet Cabot
João Maria Janeiro
Jean Maillard
Gabriel Mejia Gonzalez
Holger Schwenk
Edan Toledo
Arina Turkatenko
Albert Ventayol-Boada
Rashel Moritz
Alexandre Mourachko
Surya Parimi
Mary Williamson
Shireen Yates
David Dale
Marta R. Costa-Jussà
Abstract
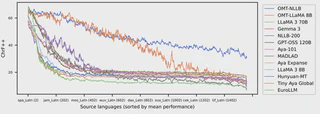
High-quality machine translation (MT) can scale to hundreds of languages, setting a high bar for multilingual systems. However, compared to the world’s 7,000 languages, current systems still offer only limited coverage: about 200 languages on the target side, and maybe a few hundreds more on the source side, supported due to cross-lingual transfer. And even these numbers have been hard to evaluate due to the lack of reliable benchmarks and metrics. We present Omnilingual Machine Translation (OMT), the first MT system supporting more than 1,600 languages. This scale is enabled by a comprehensive data strategy that integrates large public multilingual corpora with newly created datasets, including manually curated MeDLEY bitext. We explore two ways of specializing a Large Language Model (LLM) for machine translation: as a decoder-only model (OMT-LLaMA) or as a module in an encoder-decoder architecture (OMT-NLLB). Notably, all our 1B to 8B parameter models match or exceed the MT performance of a 70B LLM baseline, revealing a clear specialization advantage and enabling strong translation quality in low-compute settings. Moreover, our evaluation of English-to-1,600 translations further shows that while baseline models can interpret undersupported languages, they frequently fail to generate them with meaningful fidelity; OMT-LLaMA models substantially expand the set of languages for which coherent generation is feasible. Our leaderboard and main human-created evaluation datasets (BOUQuET and Met-BOUQuET) are dynamically evolving towards Omnilinguality and freely available.
Type
Publication
arXiv