SegAugment: Maximizing the Utility of Speech Translation Data with Segmentation-based Augmentations
Dec 1, 2023·
,
,
·
0 min read
Ioannis Tsiamas
José A. R. Fonollosa
Marta R. Costa-Jussà
Abstract
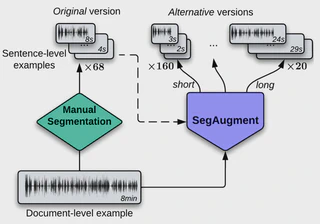
End-to-end Speech Translation is hindered by a lack of available data resources. While most of them are based on documents, a sentence-level version is available, which is however single and static, potentially impeding the usefulness of the data. We propose a new data augmentation strategy, SegAugment, to address this issue by generating multiple alternative sentence-level versions of a dataset. Our method utilizes an Audio Segmentation system, which re-segments the speech of each document with different length constraints, after which we obtain the target text via alignment methods. Experiments demonstrate consistent gains across eight language pairs in MuST-C, with an average increase of 2.5 BLEU points, and up to 5 BLEU for low-resource scenarios in mTEDx. Furthermore, when combined with a strong system, SegAugment obtains state-of-the-art results in MuST-C. Finally, we show that the proposed method can also successfully augment sentence-level datasets, and that it enables Speech Translation models to close the gap between the manual and automatic segmentation at inference time.
Type
Publication
In Findings of the Association for Computational Linguistics: EMNLP 2023